
Users can generate code for multi-core processors on the same or different architectures and benchmark usage with runtime variables. The hardware, power usage or number of cores can be adjusted and other processes can be allocated to optimise performance/W.
Clay Johnson, CEO of CacheQ Systems, described the compiler as a game changer. Software developers can “take full advantage of parallel processing power without spending years learning to code with OpenMP or MPI,” he said. “They can accelerate a single-thread algorithm with our tools to quickly compile and target any CPU with two or more cores.”
Tools in the CacheQ Complier Collection allow software developers create and deploy custom hardware accelerators for heterogeneous compute systems including FPGAS, CPUs and GPUs. the suite is modelled after the GNU Compiler Collection (GCC) tool suite, including a user interface similar to common open-source compilers. It requires limited code modification which shortens development time, explains the company.
The tool suite enables compilation, linting and error detection, performance prediction, profiling, debug and visualisation of the generated virtual engine. The CacheQ Compiler Collection supports C code and C++ through hybrid access of an exported function call.
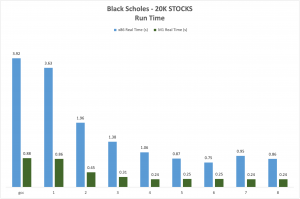
The company provides benchmarks for high-end servers and consumer electronic devices, for example, simulation of an Apple M1 processor with two cores outperformed the x86 chip with 11 cores and an M1 processor with four cores performed 210% faster than the x86 with 12 cores. Overall, the compiler performed 1,476% faster than the single-threaded GCC running on x86 using the CacheQ Compiler Collection performed on the same code.
The compiler tools are shipping now through a limited access program.