열 압축 옵션의 경우 PostgreSQL 14는 새로운 압축 방법 LZ4를 제공합니다. 기존 TOAST의 PGLZ 압축 방식에 비해 LZ4 압축이 더 빠릅니다. 이 문서에서는 전체 옵션을 사용하고 다른 압축 알고리즘과 성능을 비교하는 방법을 설명합니다.
배경
PG에서 페이지는 데이터를 저장하는 단위이며 기본값은 8KB입니다. 일반적으로 데이터 행은 여러 페이지에 걸쳐 저장할 수 없습니다. 그러나 일부 가변 길이 데이터 유형이 있으며 저장 데이터가 대학의 한 페이지를 초과할 수 있습니다. 전체 제한을 극복하기 위해 큰 필드는 압축되거나 여러 물리적 행으로 분할됩니다. 이 기술은 TOAST입니다.
기본적으로 테이블에 가변 길이 열이 있고 행 데이터의 크기가 TOAST_TUPLE_THRESHOLD(기본값 2KB)를 초과하면 TOAST가 트리거됩니다. 먼저 데이터가 먼저 압축됩니다. 압축 후에도 여전히 너무 크면 스토리지가 오버플로됩니다. 열 저장 전략이 EXTERNAL/PLAIN을 지정하는 경우 압축이 금지됩니다.
PG14 이전에 TOAST는 하나의 압축 알고리즘 PGLZ(PG 내장 알고리즘)만 지원합니다. 그러나 다른 압축 알고리즘은 PGLZ보다 빠르거나 압축 비율이 더 높을 수 있습니다. PG4에는 새로운 압축 옵션 LZ14 압축이 있으며, 이는 속도로 알려진 무손실 압축 알고리즘입니다. 따라서 TOAST 압축 및 압축 해제 속도를 높이는 데 도움이 될 것으로 기대할 수 있습니다.
LZ4를 사용하는 방법?
LZ4 압축 기능을 사용하려면 컴파일 시 -with-lz4를 지정하고 운영 체제의 LZ4 라이브러리를 따라야 합니다. PG 인스턴스의 TOAST 기본 압축 알고리즘은 GUC 파라미터 default_toast_compression을 통해 지정할 수 있습니다. postgresql에 있을 수 있습니다. conf에서 구성하면 SET 명령을 통해 현재 연결만 변경할 수도 있습니다.
postgres=# SET 기본_토스트_압축=lz4;
SET를
CREATE TABLE에서 테이블을 생성할 때 열 압축 알고리즘을 지정합니다.


d+ 명령을 사용하여 모든 열에 대한 압축 알고리즘을 볼 수 있습니다. 열이 압축 알고리즘을 지원하지 않거나 지정하지 않으면 압축 열에 공백이 표시됩니다. 위의 예에서 id 열은 압축 알고리즘을 지원하지 않고 col1 열은 PGLZ를 사용하고 col2는 LZ4를 사용하고 col3은 압축 알고리즘을 지정하지 않으면 기본 압축 알고리즘을 사용합니다.
ALTER TABLE을 통해 열 압축 알고리즘을 수정할 수 있지만 수정된 알고리즘은 전체 명령이 실행된 후에만 삽입 데이터에 영향을 미친다는 점에 유의해야 합니다.
postgres=# INSERT INTO tbl VALUES (1, repeat('abc',1000), repeat('abc',1000), repeat('abc',1000));
0 1 삽입
postgres = # ALTER TABLE tbl ALTER COLUMN col1 SET COMPRESSION lz4;
ALTER TABLE
postgres=# INSERT INTO tbl VALUES (2, repeat('abc',1000), repeat('abc',1000), repeat('abc',1000));
0 1 삽입
postgres=# SELECT 아이디,
postgres-# pg_column_compression(id) AS 압축_colid,
postgres-# pg_column_compression(col1) AS 압축_col1,
postgres-# pg_column_compression(col2) AS 압축_col2,
postgres-# pg_column_compression(col3) AS 압축_col3
postgres-# FROM tbl;
id | 압축_colid | 압축_col1 | 압축_col2 | 압축_col3
---+-----------------------------------
1 | | pglz | lz4 | lz4
2 | | lz4 | lz4 | lz4
(2열)
압축 알고리즘을 수정하기 전에 삽입된 행에 대해 압축 알고리즘이 PGLZ에서 LZ1로 수정되더라도 col4은 여전히 PGLZ 압축 알고리즘을 사용하는 것을 볼 수 있습니다. (그래서 수정 후 압축 해제에는 어떤 알고리즘을 사용해야 할까요?)
다른 테이블에서 데이터를 스캔하여 CREATE TABLE과 같이 이 테이블에 삽입하는 경우 유의하십시오. . . 같이. . . 또는 INSERT INTO. . . 선택하다. . . , 삽입된 데이터가 사용하는 압축 알고리즘은 여전히 원본 데이터의 압축 방식을 사용합니다. pg_dump 및 pg_dumpall도 토스트 압축 해제 옵션을 추가했습니다. 전체 옵션을 사용한 후에는 TOAST 압축 옵션이 덤프되지 않습니다.
성능 비교
LZ4 및 PGLZ의 압축률과 압축 속도를 테스트했습니다. 그리고 압축되지 않은 데이터의 테스트 결과를 추가했습니다(지정된 저장 전략은 EXTERNAL입니다). 압축되지 않은 데이터의 경우 시간이 많이 걸리는 압축 및 압축 해제가 없지만 데이터를 읽고 쓰는 시간이 늘어납니다.
테스트에 사용된 데이터: PG 문서(데이터 라인당 하나의 HTML 파일); HTML, 텍스트, 소스 코드, 실행 가능한 바이너리 파일 및 그림을 포함하여 SilesiaCorpus에서 제공하는 데이터
시험기 사용인텔? 제온? 실버 4210 CPU @2.20GHz, 10코어/20스레드/2소켓。
pgbench를 사용하여 SQL 문의 실행 시간을 테스트하고 pg_table_size를 사용하여 테이블 대학을 확인합니다(각 실행 전에 VACUUM FULL을 실행하여 데드 레코드의 영향을 제거).
압축비
PGLZ 및 LZ4의 압축률은 모두 반복되는 데이터에 따라 다릅니다. 반복되는 튜플이 많을수록 압축률이 높아집니다. 그러나 이러한 압축률이 좋지 않다고 PG에서 평가하면 데이터 크기가 임계값에 도달하더라도 압축이 수행되지 않습니다. 압축은 디스크 공간을 효율적으로 절약하지 못하기 때문에 압축 해제 잠금을 위한 추가 시간과 리소스 소모도 가져옵니다.
현재 PG14에서 PGLZ는 최소 25%의 압축률을 요구하는 반면 LZ는 압축되지 않은 데이터보다 작을 뿐입니다. LZ4, PGLZ 테이블 및 압축되지 않은 테이블의 크기를 비교했습니다. 대부분의 시나리오에서 PGLZ의 압축률이 약간 더 우수하고 압축률은 2.23으로 평가되며 LZ4의 압축률은 2.07임을 알 수 있습니다. 이것은 PGLZ가 디스크 공간의 7%를 절약할 수 있음을 의미합니다.
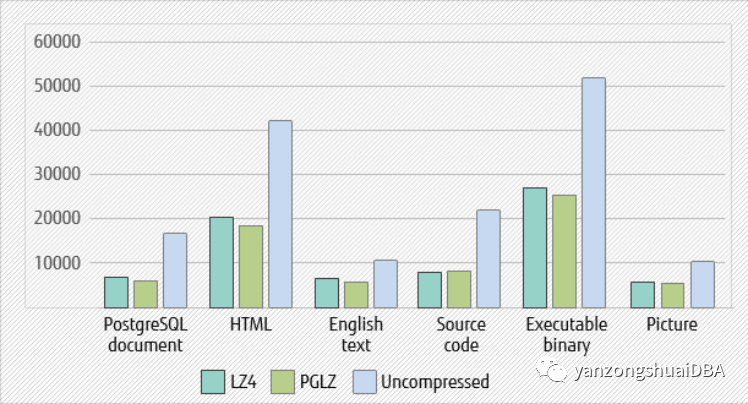

그림 1 - 테이블 크기 비교(KB)
압축/감압 속도
TOAST 데이터는 삽입 및 쿼리 중에 압축 및 압축 해제됩니다. 따라서 다양한 압축 알고리즘의 영향을 확인하기 위해 몇 가지 SQL 문을 실행했습니다.
먼저 LZ, PGLZ를 사용할 때와 압축을 사용하지 않을 때의 INSERT 문의 성능을 비교한다. 압축되지 않은 데이터에 비해 LZ4는 조금 더 시간이 걸리고 PGLZ는 더 많은 시간이 걸리는 것을 알 수 있습니다. LZ4의 압축 시간은 PGLZ보다 평균 20% 짧습니다. 이것은 매우 중요한 개선 사항입니다.
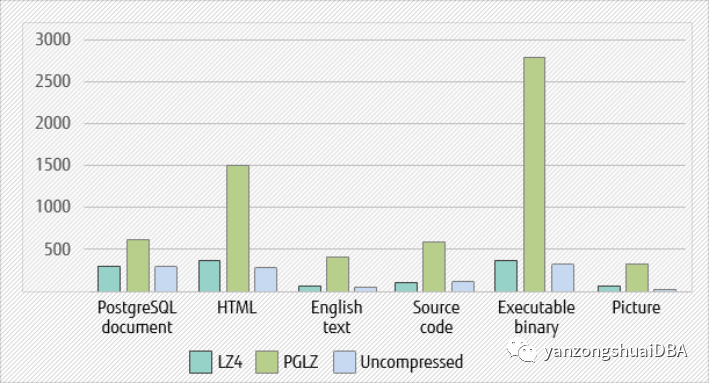

그림 2 - INSERT 성능 비교
아래의 SELECT를 비교하십시오. LZ4는 PGLZ와 비교하여 20%의 시간을 절약할 수 있으며 압축되지 않은 데이터와 큰 차이가 없습니다. 감압 비용이 매우 낮은 수준으로 감소했습니다.
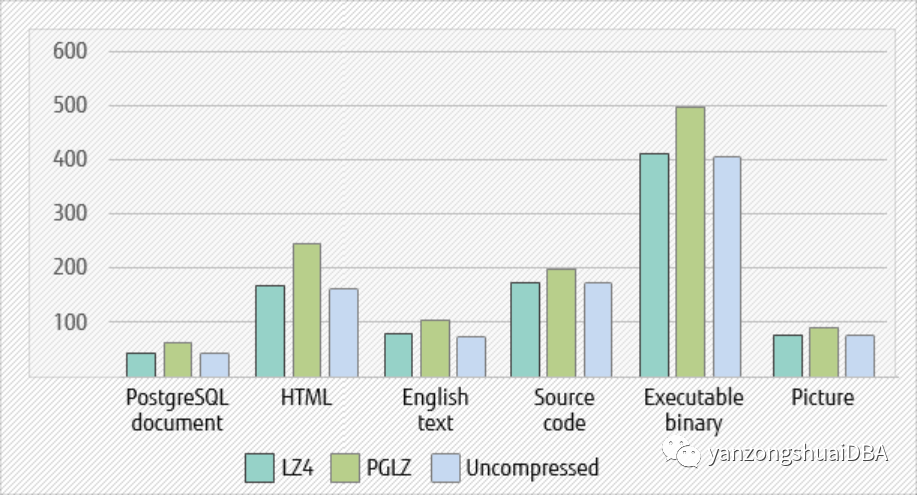

그림 3 - SELECT 성능 비교
16개 클라이언트의 동시 INSERT 문을 비교합니다. PGLZ와 비교하여 LZ4를 사용한 단일 대용량 파일(HTML, 영문 텍스트, 소스 코드, 바이너리 실행 파일, 그림)의 압축 성능은 60% -70% 더 빠릅니다. 여러 개의 작은 파일(PG 파일)을 삽입해도 성능이 향상되지 않습니다. 압축되지 않은 데이터와 비교할 때 엄청난 개선이 있습니다. 압축을 사용하면 디스크에 기록되는 데이터 양이 줄어든다고 추측됩니다.
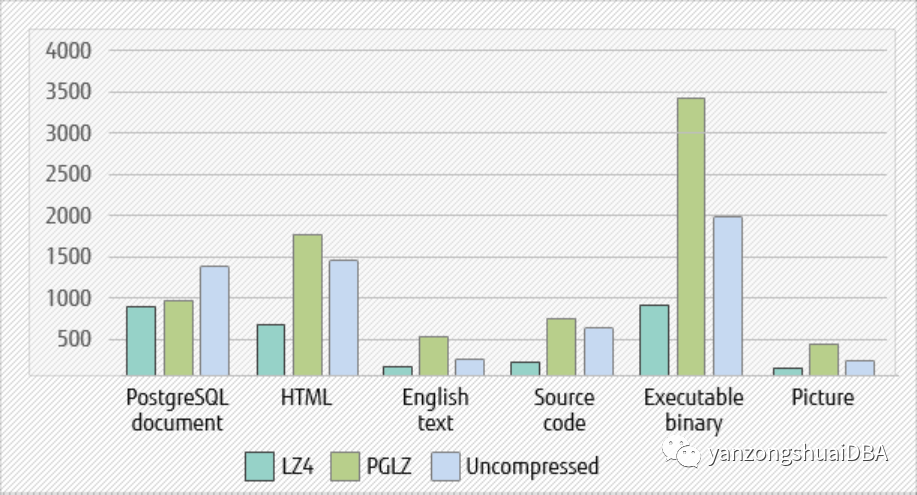
그림 4 - 16개 클라이언트와 INSERT 성능 비교
16개의 클라이언트 SELECT로 LZ4는 대부분의 시나리오에서 PGLZ보다 더 나은 성능을 보입니다.
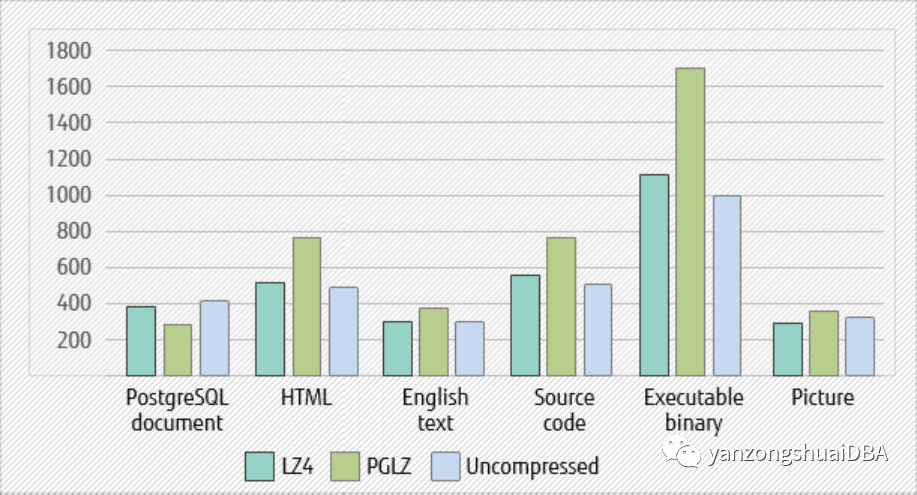
그림 5 - 16개 클라이언트와 SELECT 성능 비교
또한 문자열 함수 SELECT 및 UPDATE를 사용하여 텍스트 처리 속도를 비교합니다. LZ4는 전체 장면에서 PGLZ보다 낫습니다. 압축되지 않은 데이터와 비교하여 LZ4 압축 알고리즘의 데이터는 거의 동일한 기능 처리 속도를 가지며 LZ4 알고리즘은 문자열 연산 속도에 거의 영향을 미치지 않습니다.
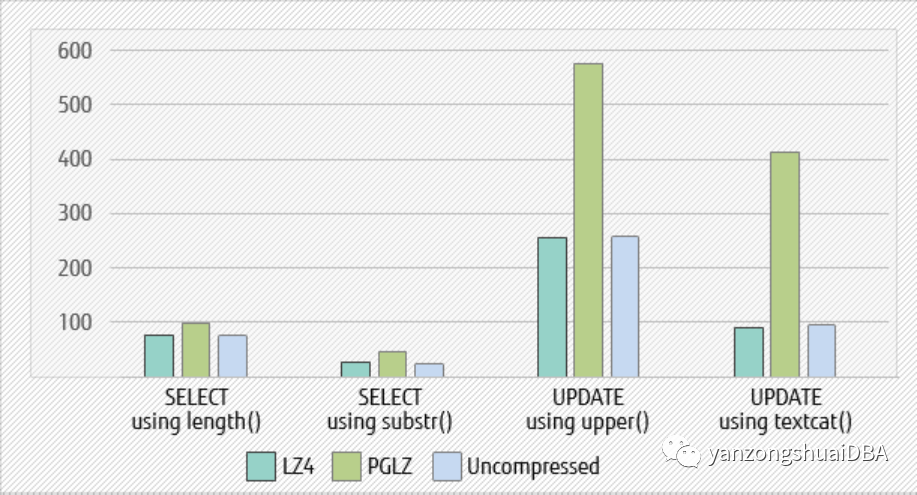
그림 6 - 문자열 함수를 사용한 성능 비교
PGLZ에 비해 LZ4는 TOAST 데이터를 보다 효율적으로 압축 및 압축 해제하고 우수한 성능을 제공합니다. 압축되지 않은 데이터와 비교하면 쿼리 속도가 거의 동일하고 PGLZ에 비해 삽입이 80% 더 빠릅니다. 물론 일부 시나리오에서는 압축률이 그리 좋지 못하지만, 실행 속도를 높이고 싶다면 LZ4 알고리즘을 사용하는 것을 강력히 추천한다.
또한 주의를 기울여야 하고 테이블의 데이터가 압축에 적합한지 고려해야 합니다. 압축률이 좋지 않으면 여전히 숫자 압축을 시도한 다음 포기합니다.램자원 낭비, 데이터 삽입 속도에 큰 영향을 미칩니다.
미래
LZ4는 TOAST의 압축 및 압축 해제 성능을 크게 향상시켰습니다. LZ4 외에도 Zstandard와 같은 다른 많은 압축 알고리즘이 있습니다. Zstandard를 지원하는 사용자는 PGLZ보다 더 나은 압축률을 얻을 수 있습니다. LZ4 HC는 LZ98.5 압축 해제보다 4%의 압축 속도를 가지지만 압축률을 크게 높일 수 있습니다. PG의 미래 버전에서 더 많은 압축 알고리즘을 사용할 수 있기를 바랍니다.
TOAST 외에 다른 장면도 압축해야 합니다. 내가 아는 한, 현재 개발 버전은 이미 WAL의 LZ4 압축을 지원하는데, 이는 흥미로운 기능입니다.