Como el caballo de batalla de semiconductor memoria, la DRAM ocupa un lugar único en la industria gracias a su gran capacidad de almacenamiento y su capacidad para alimentar rápidamente datos y códigos de programa al procesador host.
Últimamente, este héroe anónimo de la placa de circuito ha estado pasando a un segundo plano frente a sus homólogos lógicos, a medida que surge una ola de FPGA, CPU, GPU, TPU y ASIC aceleradores personalizados de alto rendimiento para satisfacer las demandas masivas de procesamiento de datos de la IA predictiva y generativa. aplicaciones. La pura densidad informática de estos aceleradores de IA que emergen rápidamente está rompiendo incluso las expectativas más ambiciosas, y la cantidad de núcleos de procesador dentro de los servidores de los centros de datos continúa aumentando.
Sin embargo, un crecimiento tan explosivo ha tenido consecuencias, dado que el escalamiento de lógica avanzada continúa superando al escalamiento de DRAM. Esta brecha contribuye a un desajuste de rendimiento cada vez mayor entre los dos que amenaza con comprometer el rendimiento del servidor al obligar a los procesadores de alta velocidad (y costosos) a desperdiciar ciclos de cómputo mientras esperan que la memoria principal se ponga al día.
Un nuevo enfoque para el diseño de interfaces DRAM
Por supuesto, esos desequilibrios no son nada nuevo. La naturaleza misma del modelo clásico de Von Neumann especifica el desacoplamiento del procesador y la memoria, lo que crea un cuello de botella que impide a los diseñadores optimizar cada ciclo de cómputo. Con las hojas de ruta de inversión en diseño y fabricación de la industria más o menos ligadas a este paradigma arquitectónico en el futuro previsible, necesitamos un nuevo enfoque para acercar los procesadores y la memoria.




De hecho, los diseñadores de DRAM se están apresurando a cerrar la brecha, sobre todo con la introducción de DRAM DDR5 de tercera generación de alta velocidad y alta capacidad. Pero se debe hacer más para combinar la computación y la memoria. Esa fue la motivación que impulsó a Renesas a lanzar recientemente un controlador de reloj registrado (RCD) y un controlador de reloj de cliente (CKD) para servidores DRAM DDR5 de tercera generación y sistemas cliente en toda nuestra cartera de interfaces de memoria para módulos de memoria dual en línea (DIMM). placas base y aplicaciones integradas.
Los nuevos IC DDR5 RCD y DDR5 CKD permiten DIMM de próxima generación con velocidades de hasta 6400 y 7200 megatransferencias por segundo (MT/s), respectivamente, un aumento con respecto a las velocidades de transferencia actuales de 5600 MT/s. El RCD DDR3 Gen 5 de Renesas está diseñado para DIMM registrados (RDIMM). El CKD es el primero en la industria en interactuar con DIMM de contorno pequeño (SODIMM), DIMM sin búfer (UDIMM), DIMM para juegos de alto rendimiento y aplicaciones con memoria baja para plataformas de clientes.

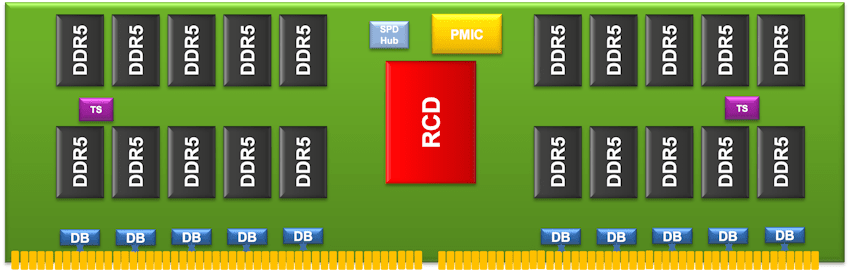
Juntos, estos nuevos controladores permiten una jerarquía de memorias que funcionan en diferentes niveles de rendimiento, potencia y capacidad. Se espera que su adopción impulse el crecimiento de los llamados “chiplets”, una forma emergente de computación heterogénea que converge componentes con diferentes funciones, nodos de proceso y características eléctricas. La computación heterogénea también está impulsando la investigación de nuevos enfoques para la memoria y la lógica dentro del dispositivo y módulo, dentro del servidor y en todo el bastidor del servidor.
La importancia de la colaboración ecosistémica
No logramos este avance en el vacío. Trabajando en estrecha colaboración con el organismo de estándares JEDEC, Renesas está facilitando un ecosistema de socios de desarrollo y sirve como pegamento que mantiene unidos a los fabricantes de DRAM y DIMM, CPU, GPU y otros proveedores de lógica, diseñadores de servidores e incluso operadores de computación a hiperescala como Amazon, Google y Microsoft. . Además de establecer una hoja de ruta compartida e indicadores clave de rendimiento, el colectivo garantiza la verificación del diseño y las pruebas de interoperabilidad a nivel de dispositivo, módulo y sistema, y en todas las aplicaciones de software relevantes.
El imperativo de una colaboración estrecha también nos llevó a unirnos al consorcio Compute Express Link™ (CXL™). El consorcio apunta a desarrollar estándares de código abierto y especificaciones técnicas para la interconexión de centros de datos. Esto incluye una estructura de memoria de alta velocidad que logra paridad de rendimiento con diversas formas de arquitecturas de sistemas informáticos.
En última instancia, nuestro objetivo en Renesas es capacitar a los arquitectos de dispositivos, módulos y sistemas para que rompan las restricciones de diseño convencionales. Juntos, podemos liberar el potencial de una arquitectura de memoria informática cooptimizada y satisfacer mejor las necesidades de aplicaciones de IA cada vez más sofisticadas y con uso intensivo de computación.
Fuente: https://www.slw-ele.com/closing-the-performance-gap-between-dram-and-ai-processors.html