
"Entwickeln" ist hier das wichtige Wort, da die Forschung Honalgorithmen für synthetische Datensätze und nicht für echte Big Data umfasst.
"Grafiken werden häufig verwendet, um reale Objekte in vielen Bereichen wie sozialen Netzwerken, Business Intelligence, Biologie und Neurowissenschaften darzustellen und zu analysieren", sagte Kaist. „Beim Entwickeln und Testen von Algorithmen für ein großes Diagramm wird normalerweise ein synthetisches Diagramm anstelle eines realen Diagramms verwendet. Dies liegt daran, dass das Teilen und Verwenden großer realer Diagramme sehr begrenzt ist, da sie proprietär sind oder praktisch nicht erfasst werden können. “
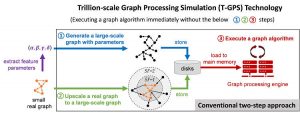
Laut Kaist erfolgt die Entwicklung und Erprobung von Graph-Algorithmen herkömmlicherweise über den folgenden zweistufigen Ansatz:
Schritt eins generiert ein synthetisches Diagramm und speichert es auf Datenträgern. Das Diagramm wird normalerweise entweder durch parameterbasierte Generierung oder durch Hochskalieren des Diagramms generiert. Ersteres extrahiert eine kleine Anzahl von Parametern, die einige Eigenschaften eines bestimmten realen Diagramms erfassen können, und generiert das synthetische Diagramm mit den Parametern. Letzteres skaliert a Geben Sie einem größeren Diagramm ein reales Diagramm, um die Eigenschaften des ursprünglichen realen Diagramms so weit wie möglich zu erhalten.
In Schritt zwei wird der gespeicherte Graph in den Hauptspeicher einer Graphverarbeitungs-Engine wie Apache GraphX geladen und ein bestimmter Graph-Algorithmus auf der Engine ausgeführt. „Da der Graph zu groß ist, um in den Hauptspeicher eines einzelnen Computers zu passen, läuft die Graph-Engine normalerweise auf einem Cluster von mehreren zehn oder Hunderten von Computern“, sagte Kaist. „Daher sind die Kosten des herkömmlichen zweistufigen Ansatzes hoch . ”
Das koreanische Team generiert und speichert kein großformatiges synthetisches Diagramm.
Stattdessen wird der anfängliche kleine reale Graph in den Hauptspeicher geladen. Dann wurde der Graph-Algorithmus unter Verwendung einer als T-GPS bezeichneten Technik (Grafikverarbeitungssimulation im Billionen-Maßstab) mit dem kleinen realen Graphen konfrontiert, als ob der große synthetische Graph, der aus dem realen Graphen erzeugt werden sollte, im Hauptspeicher vorhanden wäre, sagte Kaist Nach Abschluss des Algorithmus liefert T-GPS das gleiche Ergebnis wie der herkömmliche zweistufige Ansatz.
„Die Schlüsselidee von T-GPS besteht darin, nur den Teil des synthetischen Graphen zu generieren, auf den der Algorithmus im laufenden Betrieb zugreifen muss, und die Grafikverarbeitungs-Engine so zu ändern, dass der im laufenden Betrieb erzeugte Teil als der Teil des tatsächlich erzeugten synthetischen Graphen erkannt wird. Sagte Kaist.
T-GPS verarbeitete einen Graphen von einer Billion Kanten auf einem Computer, während der herkömmliche zweistufige Ansatz einen Cluster von elf Computern derselben Spezifikation benötigte, um einen Graphen von einer Milliarde Kanten zu verarbeiten. T-GPS benötigte keinen Netzwerkzugriff und war bis zu 43-mal schneller als der herkömmliche Ansatz, der einen erheblichen Kommunikationsaufwand verursacht.
Die Arbeit wurde auf der IEEE ICDE 2021-Konferenz als "Grafikverarbeitungssimulation im Billionenmaßstab basierend auf Top-Down-Grafik-Upscaling" vorgestellt.