
'Phát triển' là từ quan trọng ở đây, vì nghiên cứu bao gồm các thuật toán mài dũa trên các tập dữ liệu tổng hợp hơn là trên dữ liệu lớn thực.
Kaist nói: “Đồ thị được sử dụng rộng rãi để biểu diễn và phân tích các đối tượng trong thế giới thực trong nhiều lĩnh vực như mạng xã hội, trí tuệ kinh doanh, sinh học và khoa học thần kinh. “Khi phát triển và thử nghiệm các thuật toán cho một đồ thị quy mô lớn, một đồ thị tổng hợp thường được sử dụng thay vì một đồ thị thực. Điều này là do việc chia sẻ và sử dụng các biểu đồ thực quy mô lớn là rất hạn chế do chúng thuộc sở hữu độc quyền hoặc thực tế không thể thu thập được ”.
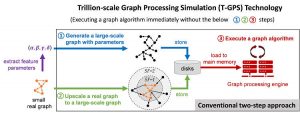
Thông thường, theo Kaist, việc phát triển và thử nghiệm các thuật toán đồ thị được thực hiện thông qua cách tiếp cận hai bước sau:
Bước một tạo một đồ thị tổng hợp và lưu trữ nó trên đĩa. Biểu đồ thường được tạo bằng cách tạo dựa trên tham số hoặc mở rộng quy mô đồ thị - phần trước trích xuất một số lượng nhỏ các tham số có thể nắm bắt một số thuộc tính của một đồ thị thực nhất định và tạo ra đồ thị tổng hợp với các tham số, phần sau tăng tỷ lệ đã cho đồ thị thực thành một đồ thị lớn hơn để bảo toàn các đặc tính của đồ thị thực ban đầu càng nhiều càng tốt.
Bước hai tải đồ thị đã lưu trữ vào bộ nhớ chính của một công cụ xử lý đồ thị, chẳng hạn như Apache GraphX, và thực hiện một thuật toán đồ thị nhất định trên công cụ. Kaist cho biết: “Vì đồ thị quá lớn để vừa với bộ nhớ chính của một máy tính, nên công cụ đồ thị thường chạy trên một nhóm vài chục hoặc hàng trăm máy tính,” do đó, chi phí của phương pháp tiếp cận hai bước thông thường là cao . ”
Nhóm nghiên cứu Hàn Quốc không tạo và lưu trữ một biểu đồ tổng hợp quy mô lớn.
Thay vào đó, nó tải đồ thị thực nhỏ ban đầu vào bộ nhớ chính. Sau đó, bằng cách sử dụng một kỹ thuật có tên là T-GPS (mô phỏng xử lý đồ thị tỷ lệ nghìn tỷ), thuật toán đồ thị đối đầu với đồ thị thực nhỏ như thể đồ thị tổng hợp quy mô lớn nên được tạo ra từ đồ thị thực tồn tại trong bộ nhớ chính, Kaist cho biết , nói thêm rằng sau khi thuật toán được thực hiện, T-GPS trả về kết quả tương tự như cách tiếp cận hai bước thông thường.
“Ý tưởng chính của T-GPS là chỉ tạo ra một phần của biểu đồ tổng hợp mà thuật toán cần truy cập khi đang di chuyển và sửa đổi công cụ xử lý đồ thị để nhận ra phần được tạo ra khi đang bay là phần của biểu đồ tổng hợp thực sự được tạo ra, ”Kaist nói.
T-GPS xử lý biểu đồ một nghìn tỷ cạnh trên một máy tính, trong khi phương pháp tiếp cận hai bước thông thường cần một nhóm mười một máy tính có cùng thông số kỹ thuật để xử lý biểu đồ một tỷ cạnh. Không cần truy cập mạng, T-GPS nhanh hơn tới 43 lần so với cách tiếp cận thông thường có chi phí liên lạc đáng kể.
Công trình đã được trình bày tại hội nghị IEEE ICDE 2021 với tên gọi 'Mô phỏng xử lý đồ thị quy mô nghìn tỷ dựa trên nâng cấp đồ thị từ trên xuống'.