
«Développer» est le mot important ici, car la recherche couvre le perfectionnement des algorithmes sur des ensembles de données synthétiques plutôt que sur de vraies données massives.
«Les graphiques sont largement utilisés pour représenter et analyser des objets du monde réel dans de nombreux domaines tels que les réseaux sociaux, l'intelligence d'affaires, la biologie et les neurosciences», a déclaré Kaist. «Lors du développement et du test d'algorithmes pour un graphe à grande échelle, un graphe synthétique est généralement utilisé à la place d'un graphe réel. En effet, le partage et l’utilisation de graphiques réels à grande échelle sont très limités, car ils sont propriétaires ou pratiquement impossibles à collecter. »
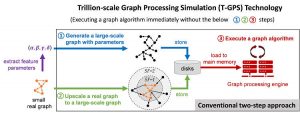
Classiquement, selon Kaist, le développement et le test d'algorithmes de graphes se font via l'approche en deux étapes suivante:
La première étape génère un graphique synthétique et le stocke sur des disques. Le graphe est généralement généré soit par génération basée sur des paramètres, soit par mise à l'échelle du graphe - le premier extrait un petit nombre de paramètres qui peuvent capturer certaines propriétés d'un graphe réel donné et génère le graphe synthétique avec les paramètres, le dernier met à l'échelle un donné un graphe réel à un graphe plus grand afin de préserver autant que possible les propriétés du graphe réel d'origine.
La deuxième étape charge le graphe stocké dans la mémoire principale d'un moteur de traitement de graphe, tel qu'Apache GraphX, et exécute un algorithme de graphe donné sur le moteur. «Étant donné que le graphique est trop volumineux pour tenir dans la mémoire principale d'un seul ordinateur, le moteur graphique fonctionne généralement sur un cluster de plusieurs dizaines ou centaines d'ordinateurs», a déclaré Kaist, «par conséquent, le coût de l'approche conventionnelle en deux étapes est élevé. . »
L'équipe coréenne ne génère et ne stocke pas de graphique synthétique à grande échelle.
Au lieu de cela, il charge le petit graphe réel initial dans la mémoire principale. Ensuite, en utilisant une technique baptisée T-GPS (simulation de traitement de graphe à l'échelle du billion), l'algorithme du graphe confronté au petit graphe réel comme si le graphe synthétique à grande échelle qui devrait être généré à partir du graphe réel existait en mémoire principale, a déclaré Kaist , ajoutant qu'une fois l'algorithme terminé, T-GPS renvoie le même résultat que l'approche classique en deux étapes.
«L'idée clé du T-GPS est de générer uniquement la partie du graphe synthétique à laquelle l'algorithme a besoin d'accéder à la volée et de modifier le moteur de traitement du graphe pour reconnaître la partie générée à la volée comme la partie du graphe synthétique réellement générée, »Dit Kaist.
T-GPS a traité un graphique d'un billion d'arêtes sur un ordinateur, tandis que l'approche conventionnelle en deux étapes nécessitait un groupe de onze ordinateurs de la même spécification pour traiter un graphique d'un milliard d'arêtes. N'ayant pas besoin d'un accès au réseau, le T-GPS était jusqu'à 43 fois plus rapide que l'approche conventionnelle qui a une surcharge de communication significative.
Le travail a été présenté lors de la conférence IEEE ICDE 2021 en tant que `` Simulation de traitement de graphique à l'échelle d'un billion de dollars basée sur une mise à l'échelle de graphique descendante ''.