
"Desarrollar" es la palabra importante aquí, ya que la investigación cubre el perfeccionamiento de algoritmos en conjuntos de datos sintéticos en lugar de grandes datos reales.
"Los gráficos se utilizan ampliamente para representar y analizar objetos del mundo real en muchos dominios, como las redes sociales, la inteligencia empresarial, la biología y la neurociencia", dijo Kaist. “Al desarrollar y probar algoritmos para un gráfico a gran escala, generalmente se usa un gráfico sintético en lugar de un gráfico real. Esto se debe a que compartir y utilizar gráficos reales a gran escala es muy limitado debido a que son propietarios o son prácticamente imposibles de recopilar ".
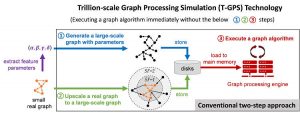
Convencionalmente, según Kaist, el desarrollo y la prueba de algoritmos de gráficos se realizan mediante el siguiente enfoque de dos pasos:
El primer paso genera un gráfico sintético y lo almacena en discos. El gráfico generalmente se genera mediante la generación basada en parámetros o mediante la ampliación del gráfico; el primero extrae una pequeña cantidad de parámetros que pueden capturar algunas propiedades de un gráfico real dado y genera el gráfico sintético con los parámetros, el segundo escala un dado un gráfico real a uno más grande para preservar las propiedades del gráfico real original tanto como sea posible.
El segundo paso carga el gráfico almacenado en la memoria principal de un motor de procesamiento de gráficos, como Apache GraphX, y ejecuta un algoritmo de gráfico determinado en el motor. “Dado que el gráfico es demasiado grande para caber en la memoria principal de una sola computadora, el motor gráfico generalmente se ejecuta en un grupo de varias decenas o cientos de computadoras”, dijo Kaist, “por lo tanto, el costo del enfoque convencional de dos pasos es alto . "
El equipo coreano no genera ni almacena un gráfico sintético a gran escala.
En cambio, carga el pequeño gráfico real inicial en la memoria principal. Luego, utilizando una técnica denominada T-GPS (simulación de procesamiento de gráficos de billones de escala), el algoritmo gráfico se enfrentó al pequeño gráfico real como si el gráfico sintético a gran escala que debería generarse a partir del gráfico real existiera en la memoria principal, dijo Kaist. , agregando que una vez finalizado el algoritmo, T-GPS devuelve el mismo resultado que el enfoque convencional de dos pasos.
“La idea clave de T-GPS es generar solo la parte del gráfico sintético a la que el algoritmo necesita acceder sobre la marcha y modificar el motor de procesamiento de gráficos para reconocer la parte generada sobre la marcha como la parte del gráfico sintético realmente generado, —Dijo Kaist.
T-GPS procesó un gráfico de un billón de bordes en una computadora, mientras que el enfoque convencional de dos pasos necesitaba un grupo de once computadoras de la misma especificación para procesar un gráfico de mil millones de bordes. Al no necesitar acceso a la red, T-GPS fue hasta 43 veces más rápido que el enfoque convencional que tiene una sobrecarga de comunicación significativa.
El trabajo se presentó en la conferencia IEEE ICDE 2021 como 'Simulación de procesamiento de gráficos a escala de billones basada en el aumento de escala de gráficos de arriba hacia abajo'.