
«Разработка» - это важное слово здесь, поскольку исследование охватывает оттачивание алгоритмов на синтетических наборах данных, а не на реальных больших данных.
«Графы широко используются для представления и анализа объектов реального мира во многих областях, таких как социальные сети, бизнес-аналитика, биология и нейробиология», - сказал Кайст. «При разработке и тестировании алгоритмов для крупномасштабного графа обычно используется синтетический граф вместо реального графа. Это связано с тем, что совместное использование и использование крупномасштабных реальных графиков очень ограничено из-за того, что они являются собственностью или их практически невозможно собрать ».
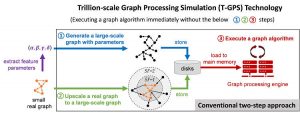
Обычно, согласно Кайсту, разработка и тестирование алгоритмов графа осуществляется с помощью следующего двухэтапного подхода:
На первом этапе создается синтетический граф и сохраняется на дисках. График обычно создается либо путем генерации на основе параметров, либо с помощью масштабирования графа - первый извлекает небольшое количество параметров, которые могут захватывать некоторые свойства данного реального графа, и генерирует синтетический граф с параметрами, последний увеличивает масштаб заданный реальный граф на более крупный, чтобы максимально сохранить свойства исходного реального графа.
На втором этапе сохраненный граф загружается в основную память механизма обработки графов, такого как Apache GraphX, и выполняет заданный алгоритм графа на механизме. «Поскольку граф слишком велик, чтобы поместиться в основную память одного компьютера, механизм графа обычно работает в кластере из нескольких десятков или сотен компьютеров», - сказал Кайст, «поэтому стоимость традиционного двухэтапного подхода высока. . »
Корейская команда не создает и не хранит крупномасштабный синтетический граф.
Вместо этого он загружает начальный небольшой реальный граф в основную память. Затем, используя метод, получивший название T-GPS (моделирование обработки графа в триллионном масштабе), алгоритм графа столкнулся с маленьким реальным графом, как если бы крупномасштабный синтетический граф, который должен быть сгенерирован из реального графа, существует в основной памяти, сказал Кайст. , добавляя, что после того, как алгоритм выполнен, T-GPS возвращает тот же результат, что и традиционный двухэтапный подход.
«Ключевая идея T-GPS заключается в создании только той части синтетического графа, к которой алгоритм должен получать доступ на лету, и модификации механизма обработки графа для распознавания части, сгенерированной на лету, как части фактически сгенерированного синтетического графа, - сказал Кайст.
T-GPS обработал граф из одного триллиона ребер на одном компьютере, в то время как традиционный двухэтапный подход требовал кластера из одиннадцати компьютеров с одинаковой спецификацией для обработки графа из одного миллиарда ребер. Не нуждаясь в доступе к сети, T-GPS был в 43 раза быстрее, чем традиционный подход, который требует значительных накладных расходов на связь.
Работа была представлена на конференции IEEE ICDE 2021 как «Моделирование обработки графиков в триллионном масштабе на основе масштабирования графиков сверху вниз».