
연구가 실제 빅 데이터가 아닌 합성 데이터 세트에서 알고리즘을 연마하는 것을 다루기 때문에 '개발'은 여기서 중요한 단어입니다.
Kaist는 "그래프는 소셜 네트워크, 비즈니스 인텔리전스, 생물학 및 신경 과학과 같은 많은 영역에서 실제 개체를 표현하고 분석하는 데 널리 사용됩니다."라고 말했습니다. “대규모 그래프에 대한 알고리즘을 개발하고 테스트 할 때 일반적으로 실제 그래프 대신 합성 그래프가 사용됩니다. 이는 대규모 실제 그래프의 공유 및 활용이 독점적이거나 수집이 사실상 불가능하기 때문에 매우 제한적이기 때문입니다.”
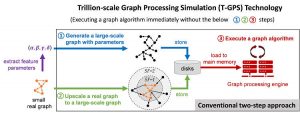
일반적으로 Kaist에 따르면 그래프 알고리즘의 개발 및 테스트는 다음 XNUMX 단계 접근 방식을 통해 수행됩니다.
XNUMX 단계는 합성 그래프를 생성하여 디스크에 저장합니다. 그래프는 일반적으로 매개 변수 기반 생성 또는 그래프 업 스케일링에 의해 생성됩니다. 전자는 주어진 실제 그래프의 일부 속성을 캡처 할 수있는 소수의 매개 변수를 추출하고 매개 변수를 사용하여 합성 그래프를 생성하고, 후자는 업 스케일링합니다. 원래 실제 그래프의 속성을 최대한 보존하기 위해 실제 그래프를 더 큰 그래프로 지정합니다.
XNUMX 단계는 저장된 그래프를 Apache GraphX와 같은 그래프 처리 엔진의 주 메모리로로드하고 엔진에서 주어진 그래프 알고리즘을 실행합니다. Kaist는“그래프가 너무 커서 단일 컴퓨터의 주 메모리에 맞지 않기 때문에 그래프 엔진은 일반적으로 수십 또는 수백 대의 컴퓨터 클러스터에서 실행됩니다. 따라서 기존의 XNUMX 단계 접근 방식의 비용이 높습니다. .”
한국 팀은 대규모 합성 그래프를 생성하고 저장하지 않습니다.
대신, 초기 작은 실제 그래프를 주 메모리에로드합니다. 그런 다음 T-GPS (XNUMX 조 규모의 그래프 처리 시뮬레이션)라는 기술을 사용하여 그래프 알고리즘은 실제 그래프에서 생성되어야하는 대규모 합성 그래프가 메인 메모리에 존재하는 것처럼 작은 실제 그래프와 마주 쳤다고 Kaist는 말했습니다. , 알고리즘이 완료된 후 T-GPS는 기존의 XNUMX 단계 접근 방식과 동일한 결과를 반환합니다.
“T-GPS의 핵심 아이디어는 알고리즘이 즉석에서 액세스해야하는 합성 그래프의 일부만 생성하고, 실제로 생성 된 합성 그래프의 일부로 즉석에서 생성 된 부분을 인식하도록 그래프 처리 엔진을 수정하는 것입니다. Kaist가 말했습니다.
T-GPS는 한 컴퓨터에서 43 조 개의 에지 그래프를 처리하는 반면, 기존의 XNUMX 단계 접근 방식은 XNUMX 억 개의 에지 그래프를 처리하기 위해 동일한 사양의 XNUMX 개 컴퓨터 클러스터가 필요했습니다. 네트워크 액세스가 필요하지 않은 T-GPS는 상당한 통신 오버 헤드가있는 기존 방식보다 최대 XNUMX 배 더 빠릅니다.
이 작업은 IEEE ICDE 2021 컨퍼런스에서 'Top-Down Graph Upscaling에 기반한 XNUMX 조 규모의 그래프 처리 시뮬레이션'으로 발표되었습니다.