
¿Cómo puedo prepararme para algo que aún no sé?
Científicos de la Universidad Técnica de Múnich (TUM) y del Instituto Fritz Haber de Berlín han abordado esta cuestión casi filosófica en el contexto del aprendizaje automático.
Aprender no es más que tomar nuevas decisiones sobre la experiencia previa. Para lidiar con una nueva situación de esta manera, es necesario haber lidiado antes con situaciones aproximadamente similares. En el aprendizaje automático, esto significa correspondientemente que un algoritmo de aprendizaje debe haber estado expuesto a datos aproximadamente similares.
Pero, ¿qué podemos hacer si hay una cantidad casi infinita de posibilidades de modo que es simplemente imposible generar datos que cubran todas las situaciones? Este problema se convierte en un gran desafío cuando se trata de un número infinito de posibles moléculas candidatas.
Los semiconductores orgánicos permiten tecnologías futuras importantes, como células solares portátiles o pantallas enrollables. Para tales aplicaciones, es necesario descubrir moléculas orgánicas mejoradas, que componen estos materiales. Las tareas de esta naturaleza utilizan cada vez más métodos de aprendizaje automático, mientras se entrena con datos de simulaciones o experimentos por computadora.
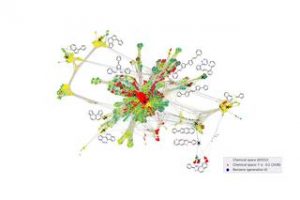
Sin embargo, se estima que el número de pequeñas moléculas orgánicas potencialmente posibles es del orden de 1033. Este abrumador número de posibilidades hace que sea prácticamente imposible generar suficientes datos para reflejar una diversidad de materiales tan grande. Además, muchas de esas moléculas ni siquiera son adecuadas para semiconductores orgánicos. Básicamente, se busca la proverbial aguja en un pajar.
El equipo del Prof. Karsten Reuter, Director del Departamento de Teoría del Fritz-Haber-Institute, y el Dr. Harald Oberhofer, Becario Heisenberg de la Cátedra de Química Teórica, abordaron este problema utilizando el llamado aprendizaje activo. En lugar de aprender de los datos existentes, el algoritmo de aprendizaje automático decide por sí mismo de forma iterativa qué datos realmente necesita para aprender sobre el problema.
Los científicos primero llevan a cabo simulaciones en unas pocas moléculas más pequeñas y obtienen datos relacionados con la conductividad eléctrica de las moléculas, una medida de su utilidad cuando se analizan posibles materiales de células solares.
Con base en estos datos, el algoritmo decide si pequeñas modificaciones en estas moléculas ya podrían conducir a propiedades útiles o si es incierto debido a la falta de datos similares. En ambos casos, solicita automáticamente nuevas simulaciones, se mejora a sí mismo a través de los datos recién generados, considera nuevas moléculas y repite este procedimiento.
En su trabajo, los científicos muestran que este enfoque es significativamente más eficiente que los algoritmos de búsqueda alternativos y cómo se pueden identificar moléculas nuevas y prometedoras de esta manera mientras el algoritmo continúa su exploración en el vasto espacio molecular. Cada semana propone nuevas moléculas que podrían marcar el comienzo de la próxima generación de células solares y el algoritmo sigue mejorando cada vez más.