
まだ知らないことに備えるにはどうすればよいですか?
ミュンヘン工科大学(TUM)とベルリンのフリッツハーバー研究所の科学者は、機械学習のコンテキストでこのほぼ哲学的な質問に取り組んでいます。
学習は、以前の経験に基づいて新しい決定を下すだけです。 このように新しい状況に対処するためには、以前にほぼ同様の状況に対処したことがある必要があります。 機械学習では、これに対応して、学習アルゴリズムがほぼ同様のデータにさらされている必要があることを意味します。
しかし、ほぼ無限の可能性があり、すべての状況をカバーするデータを生成することが単に不可能である場合、私たちは何ができるでしょうか? この問題は、無限の数の候補分子を扱うときに大きな課題になります。
有機半導体は、ポータブル太陽電池やロール可能なディスプレイなどの重要な将来の技術を可能にします。 このような用途では、これらの材料を構成する改良された有機分子を発見する必要があります。 この種のタスクでは、コンピューターシミュレーションや実験からのデータをトレーニングしながら、機械学習の方法を使用することが増えています。
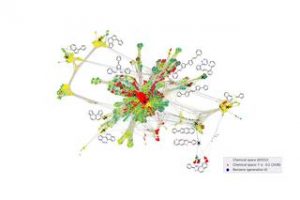
しかし、可能性のある小さな有機分子の数は1033のオーダーであると推定されます。この圧倒的な数の可能性により、このような大きな材料の多様性を反映するのに十分なデータを生成することは事実上不可能です。 さらに、これらの分子の多くは有機半導体にも適していません。 人は本質的に干し草の山の中のことわざの針を探しています。
フリッツハーバー研究所の理論部門のディレクターであるカルステンロイター教授と理論化学の議長であるハイゼンベルグ学者のハラルドオーベルホーファー博士の周りのチームは、いわゆるアクティブラーニングを使用してこの問題に取り組みました。 機械学習アルゴリズムは、既存のデータから学習する代わりに、問題について実際に学習する必要のあるデータを繰り返し決定します。
科学者は最初にいくつかの小さな分子でシミュレーションを実行し、分子の電気伝導率に関連するデータを取得します。これは、太陽電池の材料を調べる際の有用性の尺度です。
このデータに基づいて、アルゴリズムは、これらの分子への小さな変更がすでに有用な特性につながる可能性があるかどうか、または同様のデータがないために不確実であるかどうかを判断します。 どちらの場合も、自動的に新しいシミュレーションを要求し、新しく生成されたデータを介して自身を改善し、新しい分子を検討して、この手順を繰り返します。
科学者たちは、このアプローチが代替の検索アルゴリズムよりもはるかに効率的であり、アルゴリズムが広大な分子空間への探索を続けている間に、この方法で新しい有望な分子を特定する方法を示しています。 毎週、次世代の太陽電池の到来を告げる可能性のある新しい分子を提案し、アルゴリズムはどんどん良くなっています。