
아직 모르는 것에 대비하려면 어떻게 해야 합니까?
뮌헨 공과대학교(TUM)와 베를린 프리츠 하버 연구소(Fritz Haber Institute of Berlin)의 과학자들은 기계 학습의 맥락에서 거의 철학적인 이 질문을 다루었습니다.
학습은 이전 경험을 바탕으로 새로운 결정을 내리는 것에 지나지 않습니다. 이런 방식으로 새로운 상황을 처리하려면 이전에 대략 비슷한 상황을 처리한 적이 있어야 합니다. 머신러닝에서 이는 학습 알고리즘이 대략 유사한 데이터에 노출되어야 함을 의미합니다.
하지만 가능성이 거의 무한해서 모든 상황을 포괄하는 데이터를 생성하는 것이 불가능하다면 어떻게 해야 할까요? 이 문제는 무한한 수의 가능한 후보 분자를 다룰 때 주요 과제가 됩니다.
유기 반도체는 휴대용 태양전지나 롤러블 디스플레이와 같은 중요한 미래 기술을 가능하게 합니다. 이러한 응용 분야에서는 이러한 물질을 구성하는 개선된 유기 분자를 발견해야 합니다. 이러한 성격의 작업에서는 컴퓨터 시뮬레이션이나 실험의 데이터를 학습하면서 기계 학습 방법을 점점 더 많이 사용하고 있습니다.
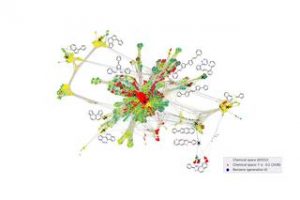
그러나 잠재적으로 가능한 작은 유기 분자의 수는 약 1033개로 추산됩니다. 이러한 압도적인 가능성으로 인해 이러한 큰 물질 다양성을 반영하기에 충분한 데이터를 생성하는 것은 사실상 불가능합니다. 게다가, 이들 분자 중 다수는 유기 반도체에도 적합하지 않습니다. 본질적으로 사람은 건초 더미에서 바늘을 찾는 것입니다.
Fritz-Haber-Institute의 이론 부서장인 Karsten Reuter 교수와 이론 화학 학과장이자 Heisenberg 학자인 Harald Oberhofer 박사를 중심으로 한 팀은 소위 능동 학습을 사용하여 이 문제를 해결했습니다. 기존 데이터에서 학습하는 대신 기계 학습 알고리즘은 문제에 대해 실제로 학습하는 데 필요한 데이터를 반복적으로 스스로 결정합니다.
과학자들은 먼저 몇 가지 더 작은 분자에 대한 시뮬레이션을 수행하고 분자의 전기 전도도와 관련된 데이터를 얻습니다. 이는 가능한 태양 전지 재료를 볼 때 유용성을 측정하는 것입니다.
이 데이터를 기반으로 알고리즘은 이러한 분자에 대한 작은 변형이 이미 유용한 특성으로 이어질 수 있는지 또는 유사한 데이터가 부족하여 불확실한지 여부를 결정합니다. 두 경우 모두 자동으로 새로운 시뮬레이션을 요청하고, 새로 생성된 데이터를 통해 자체적으로 개선하고, 새로운 분자를 고려하고, 이 절차를 반복합니다.
그들의 연구에서 과학자들은 이 접근 방식이 대체 검색 알고리즘보다 훨씬 더 효율적이며 알고리즘이 광대한 분자 공간을 계속 탐색하는 동안 이러한 방식으로 새롭고 유망한 분자를 식별할 수 있음을 보여줍니다. 매주 차세대 태양전지를 안내할 수 있는 새로운 분자를 제안하고 있으며 알고리즘은 계속해서 향상되고 있습니다.