
Hoe kan ik me voorbereiden op iets dat ik nog niet weet?
Wetenschappers van de Technische Universiteit van München (TUM) en van het Fritz Haber Instituut in Berlijn hebben deze bijna filosofische vraag behandeld in de context van machine learning.
Leren is niet meer dan nieuwe beslissingen nemen op basis van eerdere ervaringen. Om op deze manier met een nieuwe situatie om te gaan, moet men eerder met ongeveer vergelijkbare situaties te maken hebben gehad. Bij machine learning betekent dit navenant dat een leeralgoritme moet zijn blootgesteld aan ongeveer vergelijkbare gegevens.
Maar wat kunnen we doen als er een bijna oneindig aantal mogelijkheden is, zodat het simpelweg onmogelijk is om gegevens te genereren die alle situaties dekken? Dit probleem wordt een grote uitdaging bij het omgaan met een eindeloos aantal mogelijke kandidaat-moleculen.
Organische halfgeleiders maken belangrijke toekomstige technologieën mogelijk, zoals draagbare zonnecellen of oprolbare displays. Voor dergelijke toepassingen moeten verbeterde organische moleculen - waaruit deze materialen bestaan - worden ontdekt. Bij dit soort taken worden steeds vaker methoden van machine learning gebruikt, terwijl wordt getraind op gegevens uit computersimulaties of experimenten.
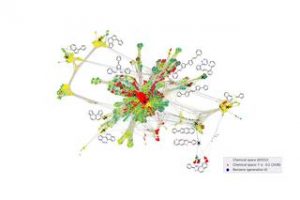
Het aantal potentieel mogelijke kleine organische moleculen wordt echter geschat op ongeveer 1033. Dit overweldigende aantal mogelijkheden maakt het praktisch onmogelijk om voldoende gegevens te genereren om een dergelijke grote materiële diversiteit weer te geven. Bovendien zijn veel van die moleculen zelfs niet geschikt voor organische halfgeleiders. Men zoekt in wezen naar de spreekwoordelijke naald in een hooiberg.
Het team rond prof. Karsten Reuter, directeur van de afdeling Theorie van het Fritz-Haber-Instituut, en dr. Harald Oberhofer, Heisenberg-geleerde bij de leerstoel Theoretische Chemie, pakten dit probleem aan met behulp van zogenaamd actief leren. In plaats van te leren van bestaande gegevens, beslist het algoritme voor machine learning iteratief zelf welke gegevens het daadwerkelijk nodig heeft om over het probleem te leren.
De wetenschappers voeren eerst simulaties uit op een paar kleinere moleculen en verkrijgen gegevens over de elektrische geleidbaarheid van de moleculen - een maatstaf voor hun bruikbaarheid bij het bekijken van mogelijke zonnecelmaterialen.
Op basis van deze data besluit het algoritme of kleine aanpassingen aan deze moleculen al tot bruikbare eigenschappen kunnen leiden of dat het onzeker is door een gebrek aan vergelijkbare data. In beide gevallen vraagt het automatisch om nieuwe simulaties, verbetert het zichzelf door de nieuw gegenereerde gegevens, beschouwt het nieuwe moleculen en herhaalt het deze procedure.
In hun werk laten de wetenschappers zien dat deze aanpak aanzienlijk efficiënter is dan alternatieve zoekalgoritmen en hoe nieuwe, veelbelovende moleculen op deze manier kunnen worden geïdentificeerd terwijl het algoritme zijn onderzoek in de enorme moleculaire ruimte voortzet. Elke week stelt het nieuwe moleculen voor die de volgende generatie zonnecellen kunnen inluiden en het algoritme wordt steeds beter en beter.