
Как я могу подготовиться к тому, чего еще не знаю?
Ученые из Технического университета Мюнхена (TUM) и Берлинского института Фрица Габера обратились к этому почти философскому вопросу в контексте машинного обучения.
Обучение - это не более чем принятие новых решений на основе предыдущего опыта. Чтобы справиться с новой ситуацией таким образом, нужно иметь дело с примерно похожими ситуациями раньше. Соответственно, в машинном обучении это означает, что алгоритм обучения должен обрабатывать примерно похожие данные.
Но что мы можем сделать, если существует почти бесконечное количество возможностей, так что сгенерировать данные, охватывающие все ситуации, просто невозможно? Эта проблема становится серьезной проблемой при работе с бесконечным числом возможных молекул-кандидатов.
Органические полупроводники позволяют использовать такие важные технологии будущего, как портативные солнечные элементы или подвижные дисплеи. Для таких применений необходимо открыть улучшенные органические молекулы, из которых состоят эти материалы. В задачах такого рода все чаще используются методы машинного обучения при обучении на данных компьютерных симуляций или экспериментов.
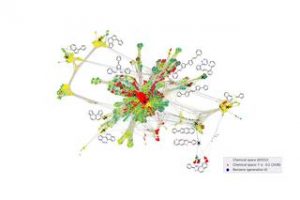
Количество потенциально возможных малых органических молекул, однако, оценивается примерно в 1033. Это огромное количество возможностей делает практически невозможным получение достаточного количества данных, чтобы отразить такое большое разнообразие материалов. Кроме того, многие из этих молекул даже не подходят для органических полупроводников. По сути, вы ищете пресловутую иголку в стоге сена.
Команда, состоящая из профессора Карстена Рейтера, директора теоретического отдела Института Фрица-Хабера, и доктора Харальда Оберхофера, ученого Гейзенберга на кафедре теоретической химии, решила эту проблему, используя так называемое активное обучение. Вместо того, чтобы учиться на существующих данных, алгоритм машинного обучения итеративно решает, какие данные ему действительно нужны, чтобы узнать о проблеме.
Сначала ученые проводят моделирование нескольких более мелких молекул и получают данные, относящиеся к их электропроводности, что является показателем их полезности при рассмотрении возможных материалов солнечных элементов.
Основываясь на этих данных, алгоритм решает, могут ли небольшие модификации этих молекул уже привести к полезным свойствам или это является неопределенным из-за отсутствия подобных данных. В обоих случаях он автоматически запрашивает новые модели, улучшает себя с помощью вновь созданных данных, рассматривает новые молекулы и продолжает повторять эту процедуру.
В своей работе ученые показывают, что этот подход значительно более эффективен, чем альтернативные алгоритмы поиска, и как таким образом можно идентифицировать новые, многообещающие молекулы, пока алгоритм продолжает свое исследование огромного молекулярного пространства. Каждую неделю он предлагает новые молекулы, которые могут открыть новое поколение солнечных элементов, и алгоритм становится все лучше и лучше.