
予想されるロボットは、計画と制御のための従来の処理に加えて、ビジョンベースの環境認識のための最大 100Top/秒の AI 処理を必要とし、ファンの必要性を回避するために低消費電力で、14nm IC の消費量は最大 5W です。
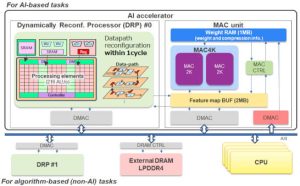
INT130 (23.9 ビット整数) データで 0.8Top/s/W (8V から) で 8Top/s を実現できる動的に再構成可能な AI アクセラレータを含む、異種混合マイクロプロセッサ アーキテクチャが選択されました。
「これは、実際のモデルではなく、最大のスパース性を持つ単一の畳み込み層で構成される理想的な CNN モデルを使用して測定されました」と同社は Electronics Weekly に語った。 「実際の AI モデルである ResNet50、YOLOV2、deeplabV3 では、9 ~ 11Top/s/W を達成しました。」
違いは、このプロセッサが重み行列内のゼロを含む計算を動的に取り除くためです。そのアーキテクチャにより、並列計算を維持しながら、より効率的な「非構造化」プルーニングを実行できます。ルネサスはこれを「N:M プルーニング」と呼んでおり、多くの重みがゼロである「疎行列」では計算が 80 ~ 90% 削減されますが、すべての重みがゼロである完全に密な行列ではパフォーマンスが最大 8Top/s に低下します。ゼロ。
そのプロセッサには 216 個の処理要素があり、XNUMX クロック サイクル内で再構成できるため、マルチステップ アルゴリズムの各ステップに合わせてハードウェアを最適化できます。
「たとえば、SLAM(位置特定とマッピングを同時に行う)では、ビジョンAI処理による環境認識と並行してロボットの位置認識を行うための複数のプログラミングプロセスが必要です」と同社は述べています。 「ルネサスは、動的再構成可能なプロセッサによる瞬時のプログラム切り替えと、AIアクセラレータとCPUの並列動作により、このSLAMを動作させることを実証しました。その結果、組み込みCPU単体と比較して、動作速度が約17倍、動作電力効率が約12倍向上しました。」
同社によれば、これは テクノロジー は、ビジョン アプリケーション向けのマイクロプロセッサ RZ/V シリーズに向けられています。
ISSCC 2024 論文 20.3: リアルタイム ロボット アプリケーション向けの 23.9nm ヘテロジニアス組み込み MPU で 0.8 倍のパフォーマンス加速可能なプルーニングを備えた 130TOPS/W @ 16V、14TOPS AI アクセラレータ
サンフランシスコで毎年開催される国際ソリッドステート回路会議である ISSCC は、IC を対象とした回路の進歩を示す世界のショーウィンドウであり、出席者は文字通り最先端の技術に触れることができます。
画像クレジット: ISSCC 2024 ルネサス